- Initiate Deployment: Go to the Models panel and click the Deploy Model button.
- Choose a Model: You can select from a curated list of popular, pre-configured models for quick deployment. In addition, you can select one of the public opensource model from Hugging Face.
Be carefull with size of the LLM versus the allocated GPU memory size…
- Configure Your Deployment:
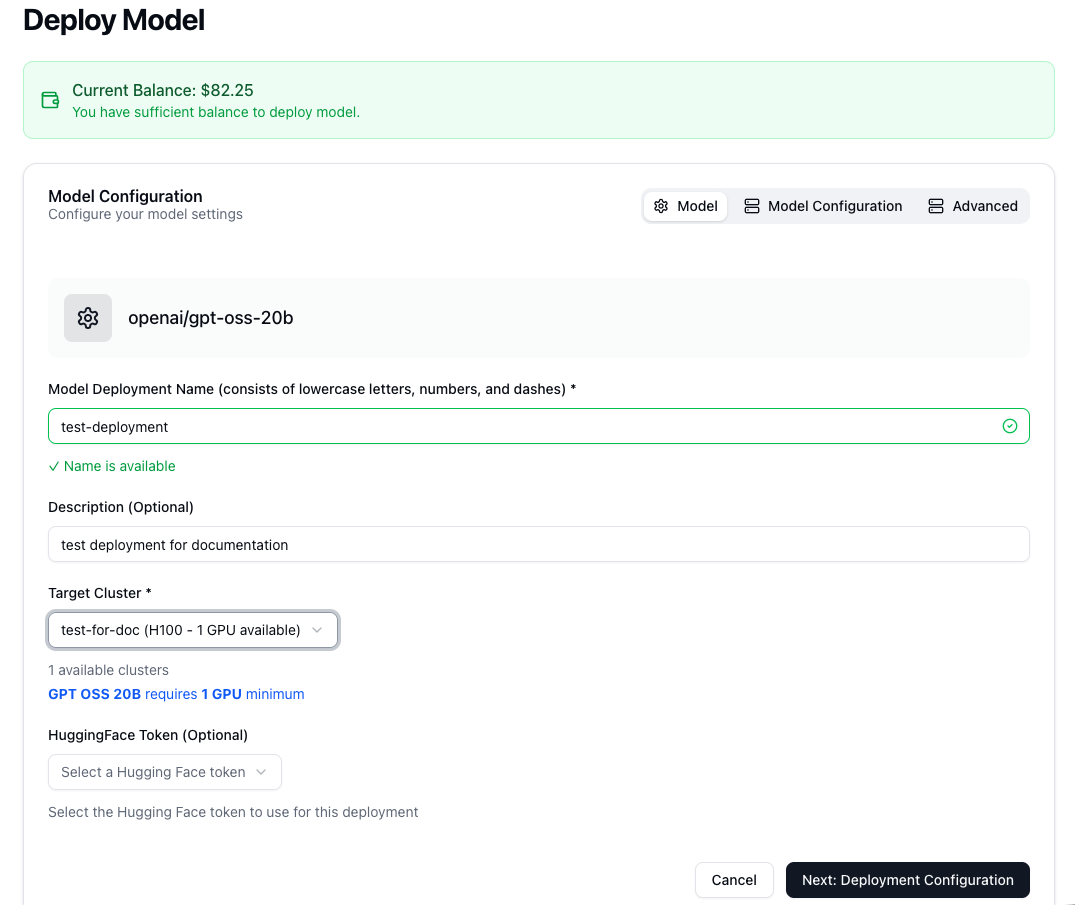
- Model: Assign a unique Deployment Name for easy identification. Select the Target Cluster from your list of acquired GPUs. If the model is private, you can add your HuggingFace Token here. The interface will automatically display the minimum number of GPUs required for the selected model.
- Model Configuration (Optional): This section allows you to fine-tune the resource allocation for your deployment. By default, Tensormesh allocates an optimized number of replicas, CPU cores, CPU memory, and GPUs. While these defaults are suitable for most use cases, advanced users can adjust these parameters to scale the model’s performance and concurrency.
- Advanced (Optional): For expert users, this section offers granular control over the underlying inference engine. You can configure technical parameters for LMCache, vLLM, and the model itself, such as maximum sequence length, concurrent request limits, and tensor parallelism. For a detailed explanation of these settings, please consult the official vLLM documentation.
- Create the Deployment: After reviewing your configuration, click Create Deployment to begin the provisioning process.
—