- Cache Hit Rate: Percentage of cache hits over time.
- Time To First Token (TTFT): Time taken to generate the first output token.
- Inter-Token Latency (ITL): Time between consecutive tokens.
- Input Throughput: Input tokens processed per second.
- Output Throughput: Output tokens processed per second.
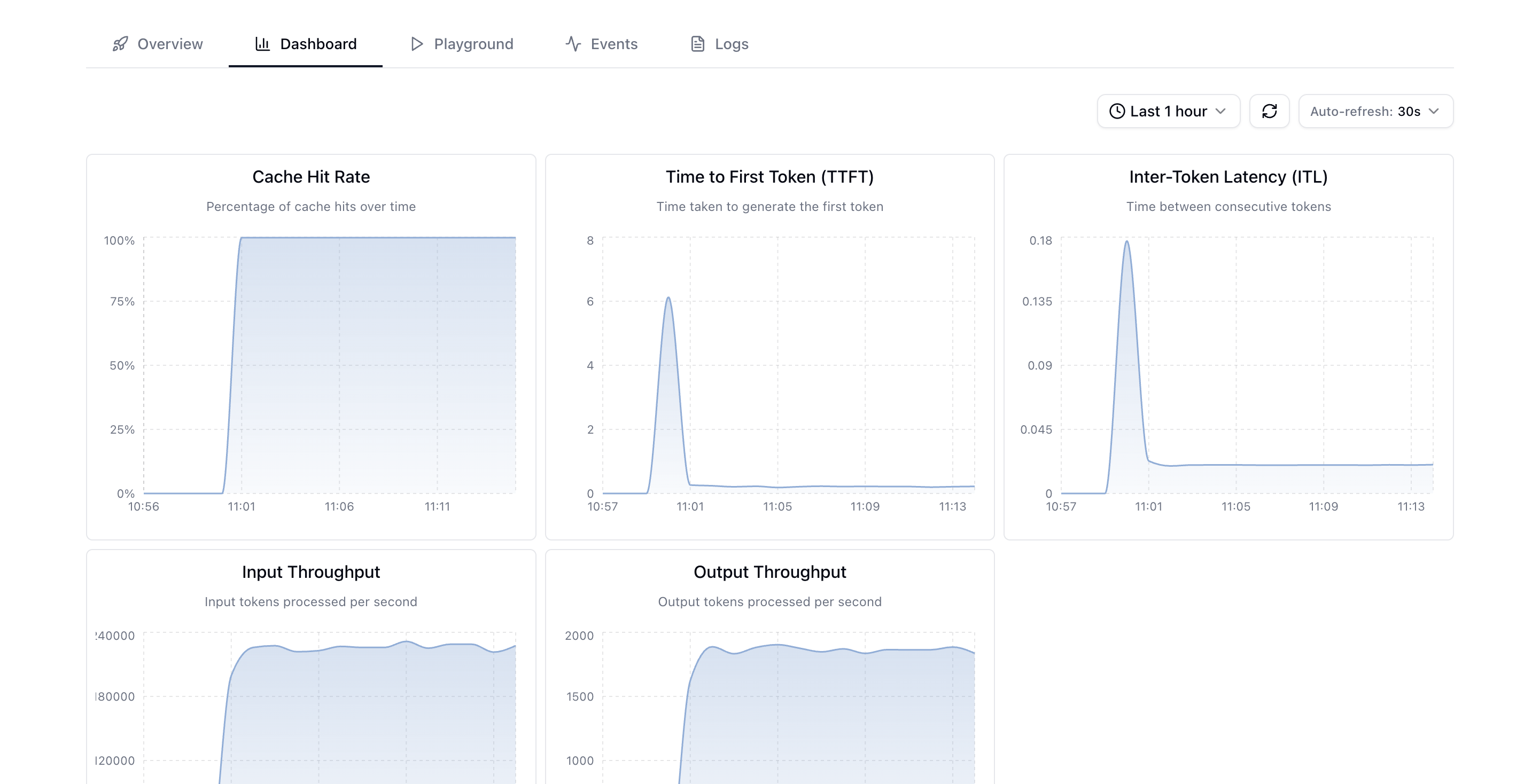
- What is a Cache Hit? A cache hit occurs when a segment of an LLM input (a reused context or prefix) is already stored in the KV cache backend and is retrieved without re-computation.
- Significance: A higher rate indicates a more efficient use of the cache, reducing computation and improving overall performance, especially for repeated or similar requests.
- Significance: TTFT directly impacts the interactive user experience in applications like chatbots and document analysis, as a shorter TTFT makes the application feel more responsive.
- Focus: ITL is primarily a concern during the decoding phase of LLM inference.
- Significance: This metric reflects the steady-state speed of the model’s output generation. A lower ITL means the output streams to the user more quickly.
- Common Measurement: Frequently measured as the query processing rate or Queries Per Second (QPS).
- Significance: Achieving high input throughput is critical because the computation associated with processing the input is the primary bottleneck for scaling LLM services to handle many simultaneous users or long inputs.
- Common Measurement: Usually measured in tokens per second or indirectly reflected in the system’s overall Query Processing Rate (QPS).
- Focus: This metric is intrinsically tied to the efficiency of the decoding phase of the LLM inference process.
- Significance: A higher output throughput means the model can generate the full response faster.