How It Works
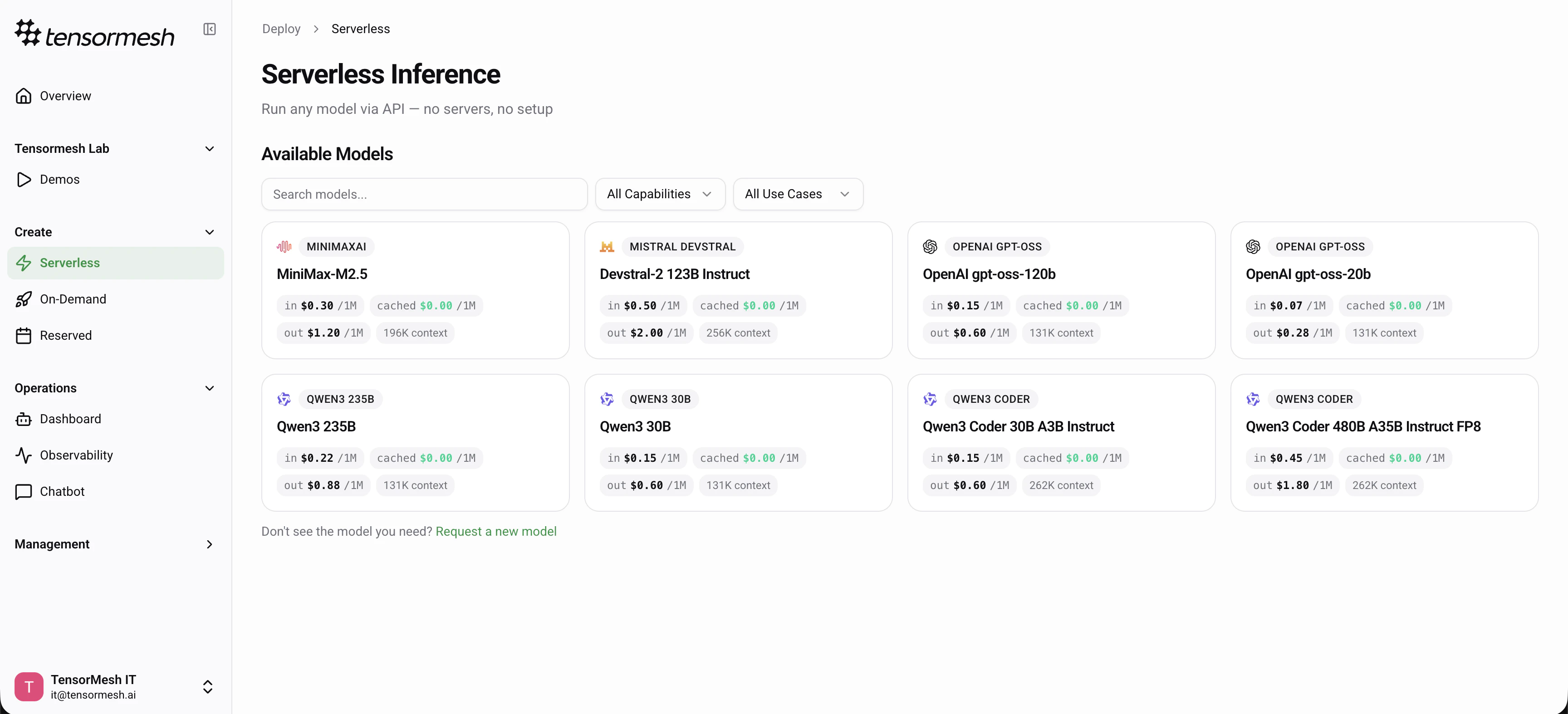
Browse Models
View all available serverless models in the model catalog. Each card shows the model name, family, context window, and per-token pricing.
Filter & Select
Use the search bar, capability filters (Coding, Reasoning, Agentic, Tool Use, Chat), or use case filters (Production APIs, Automation, Low-Latency, Research, etc.) to find the right model for your workload.
Review Details
Select a model to view its full specifications — parameter count, architecture, context window, capabilities, and detailed pricing breakdown.
Pricing
Serverless models use pay-per-token pricing. You are charged based on the number of input and output tokens processed. Cached input tokens are currently at zero cost. Current pricing for each model is displayed on the Serverless page. For a full breakdown of token usage, see Pricing Overview.Available Models
| Model | Parameters | Architecture | Context | Capabilities |
|---|---|---|---|---|
| Qwen3-Coder-480B-A35B | 480B | MoE · 35B active | 262K | Coding, Agentic, Tool Use |
| Qwen3-Coder-30B-A3B | 30.5B | MoE · 3.3B active | 262K | Coding, Agentic, Tool Use |
| Qwen3-235B-A22B | 235B | MoE · 22B active | 131K | Reasoning, Coding, Chat, Tool Use |
| MiniMax-M2.5 | 228B | MoE | 196K | Coding, Agentic, Reasoning, Tool Use |
| Devstral-2-123B | 123B | Dense | 256K | Coding, Agentic, Tool Use |
| gpt-oss-120b | 116B | MoE | 131K | Reasoning, Coding, Agentic, Tool Use |
| Qwen3-30B-A3B | 30.5B | MoE · 3.3B active | 131K | Reasoning, Chat, Coding, Tool Use |
| gpt-oss-20b | 20B | MoE | 131K | Reasoning, Coding, Agentic, Tool Use |
Choosing the Right Model
Coding Agents & SWE
Qwen3-Coder-480B for maximum capability, Qwen3-Coder-30B for a faster and cheaper option, or Devstral-2-123B for multi-file editing across large repos.
General Reasoning & Chat
Qwen3-235B for frontier-level reasoning, or Qwen3-30B for a balanced, cost-effective general-purpose option.
Low-Latency & High-Throughput
gpt-oss-20b is the most compact and fastest model — ideal for real-time assistants and high-volume API services.
Long-Context & Automation
MiniMax-M2.5 (196K context) or Qwen3-Coder-480B (262K context) for workflows that need to process large amounts of information in a single request.
Quick Start
Get your API key from Profile → API Key in the dashboard. Then call the endpoint:- cURL
- Python
The serverless API is OpenAI-compatible. You can use any OpenAI SDK or client library by pointing the base URL to
https://serverless.tensormesh.ai and using your Tensormesh API key.